����z��\
1. ����z��\�Ƃ�
(1) ��`
�u���q�̂��ׂẴy�A�ɑ��āA���q�̐����ɂ��čl�����鏈���g�ݍ��킹������������悤�ȏ����g�ݍ��킹�̏W���iJIS���j�v
(2) �ړI
ž �\�ߍ����I�Ɏ�����������āA�o�ϓI�ɐ��x�ǂ����ʂ���͂ł���悤�ɂ��邱�ƁB
ž �v���̐o���ƁA���������Ȃ����Č����I�ȍœK���������̌������s�����ƁB
(3) �g�����@�Ƃ̔�r
�g�����@�ł́A�����ΏۈȊO�̈��q�������Œ肷��̂ŁA���q�������ς�����ꍇ�ɂ́A���ʂ���������ۏ͂Ȃ��B
����\�ł́A���q�������ς���Ă���т������ʂ������݂̂̂��A�����ł���B
(4) ���
�@ 2�����n�@![]() �^
�^
2������7�v�����������i�����z�u�j
|
�� |
A |
B |
C |
D |
E |
F |
G |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
|
3 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
|
4 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
|
5 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
|
6 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
|
7 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
|
8 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
�A 3�����n�@![]() �^
�^
3������4�v�����������i�l���z�u�j
|
�� |
A |
B |
C |
D |
|
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
2 |
2 |
2 |
|
3 |
1 |
3 |
3 |
3 |
|
4 |
2 |
1 |
2 |
3 |
|
5 |
2 |
2 |
3 |
1 |
|
6 |
2 |
3 |
1 |
2 |
|
7 |
3 |
1 |
3 |
2 |
|
8 |
3 |
2 |
1 |
3 |
|
9 |
3 |
3 |
2 |
1 |
(5) �������쐬�@
��F![]() ����
����![]() �����B
�����B
|
�� |
A |
B |
C |
D |
E |
F |
G |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
|
3 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
|
4 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
|
5 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
|
6 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
|
7 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
|
8 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
��
|
�� |
A' |
D |
E |
F |
G |
|
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
2 |
2 |
2 |
2 |
|
3 |
2 |
1 |
1 |
2 |
2 |
|
4 |
2 |
2 |
2 |
1 |
1 |
|
5 |
3 |
1 |
2 |
1 |
2 |
|
6 |
3 |
2 |
1 |
2 |
1 |
|
7 |
4 |
1 |
2 |
2 |
1 |
|
8 |
4 |
2 |
1 |
1 |
2 |
2. ����z��\�̊��p
(1) ���_�}�ɂ�銄��t��
�Ⴆ�A![]() ���g����3���z�u�ł́A���̂悤�ɂȂ�B
���g����3���z�u�ł́A���̂悤�ɂȂ�B
���ۂ́A2������3���z�u�Ȃ�23��8�Ŏ����͓����Ȃ̂ŁA���s�\���g���Ӗ��͂Ȃ��B
5���z�u�ŁA���ݍ�p�̂�����݂̂�z�肵���ꍇ�́A���̂悤�ɂȂ�B
2������5���z�u�Ȃ�25��64�Ȃ̂ŁA���s�\���g���Α啝�Ɏ��������Ȃ��ł���B
���̏ꍇ�̕ϓ��y�уf�[�^�\���́A�����ŕ\�����B
![]()
![]()
|
�� |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
|
3 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
|
4 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
|
5 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
|
6 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
|
7 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
|
8 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
|
�@ |
A |
B |
A�~B |
C |
D |
E |
�� |
�Ȃ��A�����Ŋ���t�����Ȃ�������́A�S�Č덷���ɂȂ�B
(2) �������s���A�f�[�^���܂Ƃ߂�B
|
�� |
|
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
|
7 |
|
|
8 |
|
�E �����̐��F ![]()
�E �����ԍ��F ![]()
�E �f�[�^����![]()
�E ���f�[�^����![]()
(3) �J��Ԃ��̂�������̏ꍇ�A�u���b�N���Ƃ̕ϓ��Ɋւ��ē����U������s���B
(4) �Q�ϓ��Ɋւ���F������s�����߂ɁA�����𗧂Ă�B
�A������H0�F![]() �@�v���������ɉe����^���Ă���Ƃ����Ȃ��B
�@�v���������ɉe����^���Ă���Ƃ����Ȃ��B
�Η�����H1�F![]() �@�v���������ɉe����^���Ă���Ƃ�����B
�@�v���������ɉe����^���Ă���Ƃ�����B
(5) �ϓ������߂�B
�@ �C����
![]()
![]()
�A ���ϓ��i�f�[�^�S�̂̕ϓ��j
![]()
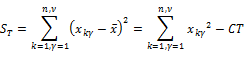
�B A�̌Q�ԕϓ��iA�̐����Ԃ̕ϓ��j
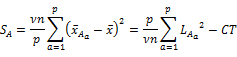
���ݍ�p�̕ϓ��E�덷�ϓ����A���s�\���Q�ԕϓ��Ɠ��l�ɂ��ċ��߂�B
���̂ق��A����@�ɂ��u���b�N�Ԃ̕ϓ�![]() ���l���ɂ����K�v������B
���l���ɂ����K�v������B
|
�@ |
A |
B |
A�~B |
C |
D |
E |
�� |
|||||||
|
���� |
A1 |
A2 |
B1 |
B2 |
A�~B 1 |
A�~B 2 |
C1 |
C2 |
D1 |
D2 |
E1 |
E2 |
��1 |
��2 |
|
���� |
|
|
|
|
|
|
|
|
||||||
|
���v |
|
|
|
|
|
|
|
|
||||||
(6) ���R�x�����߂�B
(7) ���U�����߂�B
(8) ���U�̊��Ғl�����߂�B
(9) ��^�������߂�B
(10) ���U���͕\�����B
(11) F������s���B
�����́A�v���z�u�����Ɠ����ł���B
(12) �œK�����̓_����
���ݍ�p�͗L�ӂłȂ��Ƃ���B
![]()
![]()
(13) �œK�����̋�Ԑ���i�M���x95%�j
![]()
�� �L���J��Ԃ���
![]()
3. �����@�i����z��\��p�������������j
(1) �ړI
���������̐�ւ������炵�A���S���y������B
(2) ��@
��ւ����ł������1�����q���A1�Q�Ɋ��蓖�Ă�B
���ɍ����2�����q���A2�Q�Ɋ��蓖�Ă�B
��ւ���̂Ɏ�Ԃ̂�����Ȃ�3�����q���A3�Q�Ɋ��蓖�Ă�B
|
�� |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
2 |
2 |
2 |
2 |
|
3 |
1 |
2 |
2 |
1 |
1 |
2 |
2 |
|
4 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
|
5 |
2 |
1 |
2 |
1 |
2 |
1 |
2 |
|
6 |
2 |
1 |
2 |
2 |
1 |
2 |
1 |
|
7 |
2 |
2 |
1 |
1 |
2 |
2 |
1 |
|
8 |
2 |
2 |
1 |
2 |
1 |
1 |
2 |
|
�Q |
1 |
2 |
3 |
||||