�����v��@�T�_
1. �����v��@�Ƃ�
(1) ��`
�u�i�������ɐݒ肳�ꂽ�v�i�����m�ۂ��邽�߂ɁA�{�g���l�b�N�ƂȂ�Z�p�m�ɂ���B�����̋Z�p�ƍH���v���Ƃ̈��ʊW�m�ɂ��A�œK�������߂��@�ł���B�iJIS���j�v
ž �i�������ɑ傫�ȉe����^���Ă���v���ƁA���̗v���ɂ��e���̑傫����m�邱�ƁB
ž �i�������Ɨv���i�����j�̈��ʊW�m�ɂ��A�œK���i�œK���������j�����߁A���̒l�𐄒肷�邱�ƁB
(2) �t�B�b�V���[�̎O����
�@ ����
���������Łu�J��Ԃ��̂�������v���s�����Ƃɂ��A�������ʂ��A�����ړI�ƂȂ�v���ɂ��e���Ȃ̂��A���邢�͌덷�ɂ�����͈̔͂Ȃ̂��ʂ���B
�����ɂ���āA���ݍ�p���덷�ƌ𗍂������ɁA�������邱�Ƃ��ł���B
�A �����
�����̏����┽�����������ʂɉe����^���邱�Ɓi�n���덷�j��h�����߂ɁA�u�J��Ԃ��̂�������v���A���S�Ƀ����_���ȏ��Ԃōs���B
�B �Ǐ��Ǘ���
�������ʂ��A�����ړI�ȊO�̗v���̉e�����Ȃ��悤�ɂ���B���邢�́A�Ɨ������v���Ƃ��čl���ɓ����B
���Ȃ킿�A�u�J��Ԃ��̂�������v�ɂ����āA������������҂̈Ⴂ�ɂ��e�����v���Ƃ��Ď��グ�A�����ړI�ƂȂ�v���ɂ��e���Ɣ��ʂł���悤�ɂ��āA�������ʂ̕��U���͂��s���B
2. �v���z�u����
��F�Q���q�����i�z�u�j
�Q���q�����Ƃ́A�u�����ϐ��ɉe����^�������̈قȂ���q���Ɍ�����������iJIS���j�v�ł���B
�����ł́A�S�ϓ����A�P����A�̌Q�ԕϓ��{B�̌Q�ԕϓ��{���ݍ�p�̕ϓ��{�덷�ϓ��i�Q���ϓ��j�ŕ\�����悤�ȃ��f�������肷��B
![]()
�f�[�^�\���́A
![]()
(1) �������s���A�f�[�^���܂Ƃ߂�B
�@ �v��A �ɂ��āA�����̐�p�A���Ȃ킿A1�`Ap
![]()
�A �v��B �ɂ��āA�����̐�q�A���Ȃ킿B1�`Bq
![]()
�B ��������ɂ����āA���ꂼ�ꔽ����n��̌J��Ԃ��������s���B
![]()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 2
k
n |
|
|
|
|
|
|
|
���� |
|
|
|
|
|
|
|
�͈� |
|
|
|
|
|
|
|
���v |
|
|
|
|
|
|
|
�� �����a |
|
|
|
|
|
|
|
���U |
|
|
|
|
|
|
ž �e���R�x��n-1
ž �͈�
![]()
ž �������a
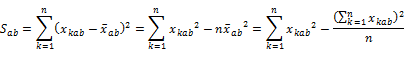
ž ���U
![]()
(2) �J��Ԃ��̂�������̏ꍇ�A�u���b�N���Ƃ̕ϓ��Ɋւ��ē����U������s���B
pq��ނ̏���A1B1�`ApBq�ɂ����āA������������x���ۂ���������B
�@ F����
�u���b�N���Ƃ̕��U���r���A�A������
![]()
���̑������A�����U�ł���Ƃ݂Ȃ��B
�A �͈͂̌���
�Ǘ��}�̊Ǘ����E�����v�Z����W������A
![]()
�Ȃ�A�����U�ł���Ƃ݂Ȃ��B
(3) ����ǂ́A�Q�ϓ��Ɋւ���F������s�����߂ɁA�����𗧂Ă�B
�A������H0�F![]() �@�v��A�������ɉe����^���Ă���Ƃ����Ȃ��B
�@�v��A�������ɉe����^���Ă���Ƃ����Ȃ��B
�Η�����H1�F![]() �@�v��A�������ɉe����^���Ă���Ƃ�����B
�@�v��A�������ɉe����^���Ă���Ƃ�����B
�A������H0�F![]() �@�v��B�������ɉe����^���Ă���Ƃ����Ȃ��B
�@�v��B�������ɉe����^���Ă���Ƃ����Ȃ��B
�Η�����H1�F![]() �@�v��B�������ɉe����^���Ă���Ƃ�����B
�@�v��B�������ɉe����^���Ă���Ƃ�����B
�A������H0�F![]() �@���ݍ�p
�@���ݍ�p![]() �������ɉe����^���Ă���Ƃ����Ȃ��B
�������ɉe����^���Ă���Ƃ����Ȃ��B
�Η�����H1�F![]() �@���ݍ�p
�@���ݍ�p![]() �������ɉe����^���Ă���Ƃ�����B
�������ɉe����^���Ă���Ƃ�����B
(4) �ϓ������߂�B
�e�ϓ����v�Z����ɂ́A���v�ƏC��������Z�o���邩�A�������a����Z�o���邩�̂ǂ��炩�ł���B
�@ �C����
![]()
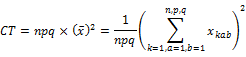
�A ���ϓ��i�f�[�^�S�̂̕ϓ��j
![]()

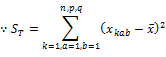
�B A�̌Q�ԕϓ��iA�̐����Ԃ̕ϓ��j
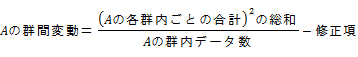
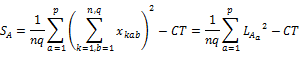
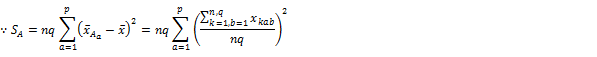
�C B�̌Q�ԕϓ��iB�̐����Ԃ̕ϓ��j
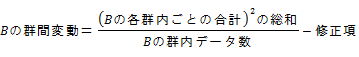
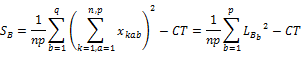
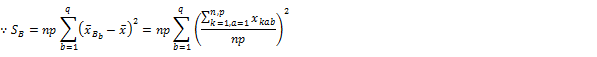
�D AB�̕ϓ��i���肳�ꂽ�u���b�NAB�Ԃ̕ϓ��j
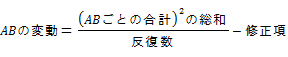
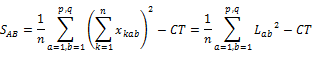
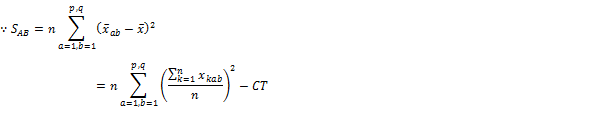
�E ���ݍ�pA�~B�̕ϓ�
���ݍ�p�Ƃ́A�݂��ɓƗ��̈��q���g�ݍ��킳�������ɁA���ʂȌ��ʂ��\��邱�Ƃ������B
![]()
�F �덷�ϓ��i�Q���ϓ��j
![]()
�܂��́A
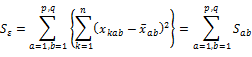
�u���b�N���Ƃ̍��v�E�Q���Ƃ̍��v
|
|
|
|
|
|
|
|
B�Q ���v |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
A�Q ���v |
|
|
|
|
|
|
|
�e�u���b�N�̃f�[�^������n�AA�e�Q�̃f�[�^������nq�AB�e�Q�̃f�[�^������np
(5) ���R�x�����߂�B
![]()
![]()
![]()
![]()
![]()
![]()
(6) ���U�����߂�B
![]()
![]()
![]()
![]()
![]()
(7) ���U�̊��Ғl�����߂�B
![]()
![]()
![]()
![]()
(8) ��^�������߂�B
![]()
![]()
![]()
(9) ���U���͕\�����B
|
�v��
|
�ϓ� S |
���R�x 𝜙 |
���U V = S /𝜙 |
���U�� F0 |
���Ғl E(V ) |
��^�� �� |
|
A |
|
|
|
|
|
|
|
B |
|
|
|
|
|
|
|
A�~B |
|
|
|
|
|
|
|
�� |
|
|
|
|
|
|
|
T |
|
|
|
|
|
|
(10) F������s���B
![]() ���ꂼ��ɂ��āA
���ꂼ��ɂ��āA
i. ![]() �Ȃ�A������H0�͊��p����A�Η�����H1���̑������B�L�Ӑ���5%�ɂėL�Ӎ�����B
�Ȃ�A������H0�͊��p����A�Η�����H1���̑������B�L�Ӑ���5%�ɂėL�Ӎ�����B
![]()
ii. ![]() �Ȃ�A������H0�͊��p����Ȃ��B�L�Ӑ���5%�ɂėL�ӂłȂ��B
�Ȃ�A������H0�͊��p����Ȃ��B�L�Ӑ���5%�ɂėL�ӂłȂ��B
![]()
�A���������̑����ꂽ���A�L�ӂłȂ��v���́A�덷�Ƀv�[�����āA���U���͕\�����߂č�蒼���B
���Ƃ��Ό��ݍ�p���L�ӂłȂ��ꍇ�́A
![]()
![]()
�Ƃ��āA���U���͂����Ȃ����B
(11) �œK�����̓_����
�u���b�N���Ƃ̕��ϒl�ƌQ���ϒl��\�ɂ���B
|
|
|
|
|
|
|
|
�Q���� |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
�Q���� |
|
|
|
|
|
|
|
i. ���ݍ�p���L�ӂ̏ꍇ
![]()
ii. ���ݍ�p���L�ӂłȂ��ꍇ
![]()
(12) �œK�����̋�Ԑ���i�M���x95%�j
i. ���ݍ�p���L�ӂ̏ꍇ
![]()
![]()
ii. ���ݍ�p���L�ӂłȂ��ꍇ
![]()
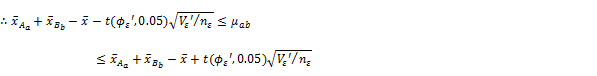
�� �L���J��Ԃ���
![]()
3. ����@
(1) �ړI
�e�����̎������s�������������B
(2) ��@
�Ⴆ��4�~4��16�����̏ꍇ�A
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
����@�ł́A16�������An�u���b�N�ɕ������čs���B
1�u���b�N�ځF16���������S�Ƀ����_���ȏ����ōs���B
2�u���b�N�ځF16���������S�Ƀ����_���ȏ����ōs���B
![]()
n�u���b�N�ځF16���������S�Ƀ����_���ȏ����ōs���B
�v���ɂ��ẮAA�v���EB�v���E���ݍ�pA�~B�E�덷�v���̂ق��ɁA�u���b�N���qN���z�肳��A���U���͂ɂ����āA�u���b�N�Ԃ̕ϓ�![]() ���l���ɂ����K�v������B
���l���ɂ����K�v������B
|
�v��
|
�ϓ� S |
���R�x 𝜙 |
���U V = S/𝜙 |
���U�� F0 |
|
A |
|
|
|
|
|
B |
|
|
|
|
|
A�~B |
|
|
|
|
|
N |
|
|
|
|
|
�� |
|
|
|
|
|
T |
|
|
|
|
(3) ���S����ז@�Ƃ̔�r
���S����ז@�ł́A�S�Ă̏����������_���ȏ��Ԃɕ��ׂčs���B
�����͊��S�����_���ł͂��邪�A�u���b�N�Ԃ̕ϓ����l�����Ȃ��̂ŁA�덷���傫���Ȃ�B
4. ��������
(1) �ړI
���������̐�ւ������炵�A���S���y������B
(2) ��@
�O�q��4�~4��16�����̏ꍇ�A
���������ł́A��ւ��������B���q�i1�����q�j���Œ肵�AA���q�i2�����q�j�̐�ւ��̂ݍs���B
�������AB���q�̌J��Ԃ��͗���@�i�܂��͊��S����ז@�j�ōs���B
�����ł͗���@���Ƃ��ċ�����Bn�u���b�N�ɕ�������B
1�u���b�N��
|
|
|
|
|
|
|
|
|
|
|
|
2�u���b�N��
|
|
|
|
|
|
|
|
|
|
|
|
![]()
n�u���b�N��
�ꎟ�덷�́AB���q�ƃu���b�N���qN�̌��ݍ�p�ɑ�������B
|
�v��
|
�ϓ� S |
���R�x 𝜙 |
���U V = S /𝜙 |
���U�� F0 |
|
B |
|
|
|
|
|
N |
|
|
|
|
|
��1 |
|
|
|
|
|
A |
|
|
|
|
|
A�~B |
|
|
|
|
|
��2 |
|
|
|
|
|
T |
|
|
|
|
�ꎟ���q�̌��萸�x�͈������A���q�E���ݍ�p�̌��萸�x�͗ǂ��B